

Fix Google Crawling Issues on your Website
Google and other search engines determine the content of your website’s pages by sending out bots (also called crawlers or spiders) to crawl and index your content. Following your internal links, it discovers and maps your website.
Whenever a user navigates to your page, Google looks for fresh or updated information and then changes its index accordingly. But how do you ensure your website is being properly crawled and indexed in Google?
The information gathered is then used with to determine where your site will rank in search engine results pages for various queries. But crawlability problems aren’t always immediately obvious and even veteran SEO professionals can overlook issues that are causing search engine bots to miss, and therefor fail to index website pages.
With this in mind, it’s obvious how important crawlability and indexability are to driving organic traffic to your website pages. The tricky part, of course is finding these issues.
In this piece, we’re going to take a look at some of the more common crawlablity problems, how to find them and how to fix them.
Finding pages search engine crawlers are missing
Before you can fix your crawling issues, you first need to find where they are occurring.
The easiest way to do this is to use the Page Indexing report in Google Search Console. This will give you a variety of ways to see which pages have been indexed and which have been requested but have not been mapped.
There are two things you need to keep in mind about this report:
- You should not expect 100% coverage – Only pages with canonical tags will be indexed.
- Indexing can take a few days – Don’t expect immediate results, as it can take a few days before search engines crawl your site. You can shorten this time frame by requesting your website be indexed, but don’t expect new pages included over night.
Why google isn’t crawling your website and how to fix it
Once you have figured out all the pages you want being indexed are not being included in search results, you need to figure out what’s preventing search bots from finding them.
Here are some common reasons certain pages are being missed:
1. Problems with the robots.txt file or Meta Tags
Checking your meta tags and the robots.txt file is a quick and straightforward way to identify and resolve common crawlability issues, which makes it one of the first things you should look into.
For example, an entire website or individual pages may go unnoticed by Google because the search engine’s crawlers are forbidden from accessing them. Or search engines may not have access to your robots.txt file because it isn’t in your root directory. These are relatively easy fixes.
There are also a few bot commands that, when executed, will prohibit search spiders from crawling a page, with the noindex meta tag being the most common culprit. Nofollow links can also inadvertently lead to pages blocked from discovery.
These parameters serve an important role when used appropriately, as they help save a crawl budget and provide bots with the exact direction they need to crawl the pages that you want to be scanned. But if they are misused, they can stop web crawlers from finding relevant pages.
For example, here is a robots.txt file from the New York Times website that contains numerous forbid commands:
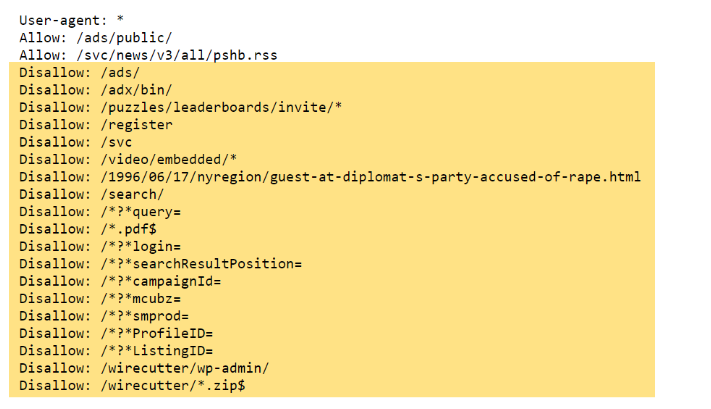
If you’re not careful, it’s easy to accidentally include pages you actually wanted indexed.
If Google cannot index some pages of your website because of crawl restrictions or your robots.txt file is preventing it from crawling (and indexing) all your pages, look for any commands that are in your robots.txt file causing problems and make the appropriate adjustments.
2. Problems with Your Sitemap
Using sitemaps helps search engines understand the structure of your site and discover the most significant pages. As a result, a problem with your sitemap may be preventing Google from crawling your web pages.
Make sure yours is accurate and up to date and includes all the pages on your site you want included in search results.
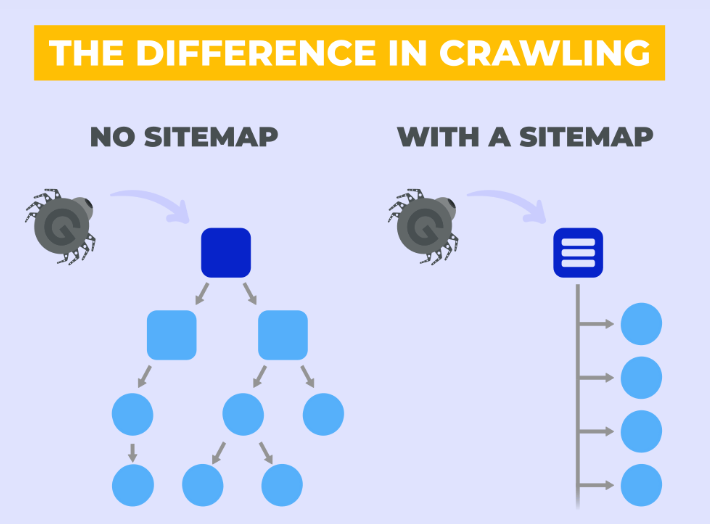
Some hosting providers automatically generate a sitemap file. If your’s doesn’t, you can use a sitemap generator to construct your own.
Once you have an XML file of your sitemap, upload it to Google Search Console GSC.
3. Poor Site Architecture
Site structure is a major factor in crawlability, as it impacts how a search engine discovers your relevant pages. If you have broken internal links or content that can’t be discovered with just a few clicks, your pages may go unnoticed.
To ensure you provide search engines with the pathways they need to discover your content and reduce crawl errors, website owners should create a well structured site with a straightforward hierarchy for internal linking.
Perform a site audit and make sure all the pages on your site are connected and fix broken links, particularly those to old or deleted URLs. Ensure you’re using follow links where you should be and that each relevant page is connected to logical counterparts.
4. Irrelevant or Missing Pages
Each website has a limited crawl budget. If yours has too many irrelevant pages, you’ll run out. Make sure Google’s bots are reaching your most important pages by going through your website and deleting any that aren’t relevant.
For example, if you have similar or duplicate content on landing pages, you may be exhausting your crawl budget on pages with little to no SEO benefit.
Similarly, missing pages can cause you problems. When visitors land on a page that doesn’t exist, they get a 404 error page. This is fairly common on e-commerce sites, especially, which are subject to changing deals and inventories.
For Google to effectively crawl your website, you will need to add any currently missing pages.
After you have listed every page that generates a 404 error, you should then set up a 301 redirect to automatically redirect these pages to active web pages.
This will improve the process that Google uses to crawl websites, but is itself not without its problems.
5. Slow Site Speed
If your site takes a long time to load, you’re forcing search bots to spend more of your crawl budget waiting for pages to load. Even worse, it’s inconvenient for human users.
Optimizing site speed is the best way to avoid this problem. Be aware of the things that can negatively impact your site performance, including uncompressed images, videos and other media files.
Replace or eliminate redundant content elements and double check that your site structure is efficient and logical. This makes it easy for web crawlers to discover one page from the previous.
You may also want to consider using a content delivery network. By using multiple servers to store your content in various locations, it connects website visitors with the server closest to their physical location to optimize loading speed.
6. Redirect Loops
Often caused by a simple typo or poor site architecture, a redirect loop occurs when one website URL is redirected to another, which in turn leads back to the first, creating an infinite loop of redirects.
If you discover your website has redirect loops, use CTRL+F to find all the files in your HTML that include “redirect” to find and fix these problems.
7. Orphan Pages
Sometimes you will have a page on your website that is not connected to the rest of the site. These URLs, called orphan pages, can’t be indexed by search engine bots because they aren’t getting crawled.
Perform a site audit to determine which, if any of your pages are isolated. Once they’re found, you can either remove them or set up a redirect in case the page has inbound links from an external site.
8. Access Restrictions
If you have premium or sensitive content in the form of blocked pages only available to registered users, search engine bots could be prevented from indexing these pages.
Having gated content is a good idea for certain pages on websites that employe a subscription or membership-based model. But if too many URLs on your site are restricted, the website’s crawlability will be negatively impacted.
Make sure your important pages (i.e., the ones you want search spiders to visit and index) are not restricted and are discoverable. If you have important content hidden behind a paywall or other gateway, makes sure the information is included in other pages in the same domain that are accessible to the public.
9. Unresponsive or Inaccessible Pages on Your Site
Google introduced mobile-first indexing in 2016. Today, more than half the traffic on search engines is made from a mobile device. If your site is not responsive and mobile-friendly, it may not be indexed.
Similarly, if you don’t follow ADA compliance guidelines, your website may not be indexed. Common accessibility issues include missing alt text, a lack of keyboard-only commands and the use of fonts that are not friendly to those with disabilities.
10. Google Penalties
Another, but hopefully unlikely reason your site could be experiencing indexing issues isn’t related to crawlability problems at all: you could have received a penalty from Google.
This could be caused by a variety of “black hat” SEO tactics, including automatically generated or duplicate content, hidden text, unnatural links or misleading redirects.
Make sure you are following Googles Webmaster Guidelines to avoid being penalized.
How to tell google crawlability problems have been fixed
Once you have identified and corrected all your internal linking, site structure and other crawlability issues, you need to notify search engines that your website is now reading to be re-crawled.
To do this, open Google Search Console and open the Page Indexing report. Click on pages that show issues and, once you have confirmed you have fixed the issue, click “Validate Fix.”
Google will then begin a validation process (which could take several weeks), and once the search engine is satisfied you have fixed the issue, add your pages to its index and start returning them for search results.
Next steps
1. Organically Improve Traffic
Once you’ve fixed the problems that are preventing your site from being indexed properly, it’s time to start driving organic traffic by optimizing these vital pages for search engines. The best way to do this is by constructing attractive, keyword-rich pages that will bring highly targeted traffic to your website.
2. Create Quality Backlinks
Backlinks, an essential Google ranking criteria, help Google determine the authority and credibility of your website. Therefore, generating high-quality backlinks will accelerate Google’s indexing of your content.
3. Build Web Pages Search Engine Bots Cannot Ignore
Your SEO efforts will only be profitable if your web pages rank at the top of SERPs. But Google’s ability to crawl and index your content alone is not sufficient to ensure this. Employ a well-rounded SEO strategy to make sure our site appears at the top of rankings and gets the traffic you deserve.
Find and eliminate crawlability problems the easy way
Whether its internal linking issues, a redirect loop, broken links or poor site structure, there are a lot of things that can cause crawlability issues. Evisio is the easiest way to find and fix them.
With regularly schedule scans of your website, it will identify things that are causing crawl errors and then provide you with step-by-step instructions for fixing them. And this is just one small piece of its functionality.
It also includes project management capabilities (including user permissions and task assignment), real-time status updates and automated reporting. It has everything you need for SEO in one convenient and easy-to-use platform.
See it for yourself. Contact us to start your free trial.
If you’re looking for SEO project management software to better manage your workflow, clients, and business – evisio.co is your solution. Try evisio.co for free here!